Detecting Suspicious Websites
Original post on Zemanta’s blog, reproduced here for posterity:
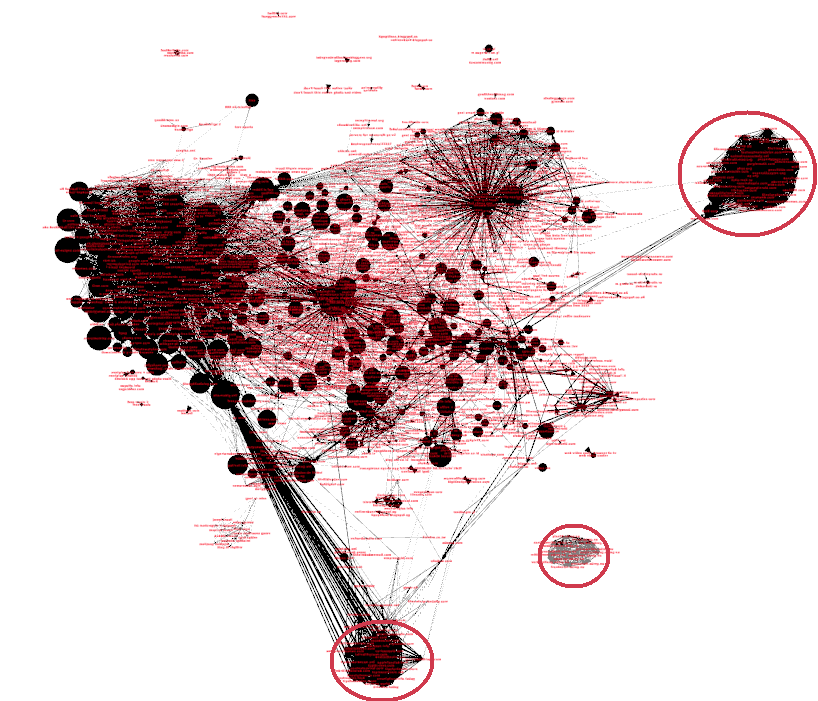 A covisitation graph of all websites with at least 100 unique visitors over a 3-day span and node size logarithmically proportional to number of visitors.
A covisitation graph of all websites with at least 100 unique visitors over a 3-day span and node size logarithmically proportional to number of visitors.
It’s every advertiser’s worst nightmare: advertising on a seemingly legitimate site only to realize that the traffic and/or clicks from that site are not the coveted genuine human interest in the ad. Instead they find fake clicks, unintentional traffic or just plain bots. In a never-ending quest for more ad revenue, website publishers scramble for ways to impersonate their more successful counterparts. However, not all approaches are as respectable as improving readability and SEO.
One pernicious tactic is sharing traffic between two or more sites. Of course, almost all websites share some of their visitors, but this percentage is small. Moreover, as the site accumulates more visitors, the probability of a large overlap occurring by chance becomes infinitesimal. This tactic is commonly used by botnets, so that the sites employing this traffic can also be unwitting targets of such schemes. For example, a botnet can, among the suspicious sites, add several well-known and respected websites, so that the apparent credibility of the malicious sites is artificially boosted.
The question is thus, can we identify these traffic-sharing websites? And if so, then how? The answer to the first question is yes, and to the second is this blog post.
Our problem lends itself nicely to a network approach called a covisitation graph [1]. We will construct a graph, such that the sites that share traffic will be tightly connected. Especially if visitors are shared between several sites, as is usually the case. We can represent all of the websites as vertices (nodes) in a graph. To encode the overlap between a pair or sites, we will use directed edges weighted between 0 and 1. This number will be the proportion of visitors from the source of the edge that were also seen on the target edge. Let A have 200 visitors, B have 1000 visitors, and the shared traffic be 100 visitors. The edge from A to B is the overlap divided by A’s visitors, or 100/200 or 0.5. Similarly, from B to A we have 100/1000 or 0.1. Of course, a network is no network if it’s completely connected. We must set an appropriate threshold to remove edges but keep the ones that are important. A simple threshold of 0.5 proved most useful in our case.
To get the full network, we must repeat this calculation for all pairs of edges. This network is useful for more than just computation, as a quick visual inspection reveals many interesting things. Tight clusters of websites that are only loosely connected to the core of the graph are precisely the aberrations we would expect when several sites band together. In graph theory, they are called cliques, and have been well researched. A well-known measure of “cliqueness” is the clustering coefficient: \(C = \frac{\text{\# of actual triangles}}{\text{\# of possible triangles}}.\) It is a number between 0 and 1, with 0 meaning that none of the node’s neighbors are connected with each other, and 1 meaning the opposite (i.e. the node and its neighbors form a clique). We can combine this number with the probability of such a cluster occurring randomly to get a sensible measure of suspicion for each site. Thus, a small clique of 2-3 sites is somewhat likely to occur, but a clique of 20 nodes warrants a closer discerning look. The circled areas in the graph at the beginning indicate exactly these occurrences. We have several groups of websites with dissimilar content where they all share each other’s traffic. One of the suspicious cliques is completely detached from the rest of the graph.
On one hand, there are going to be a lot of naturally occurring edges in the graph. Overlaps as high as 50% are not uncommon between websites of similar content. On the other hand, sites should have very few outgoing edges, especially if they are popular and have many visitors. Popular sites may have many incoming edges, but as long the sources of these edges are not connected with each other it is not going to be predicted as fraud by our methods.
Thus, out of the vast interconnected graph that is the world wide web, we can, with precision, pick out the few bad apples that are trying to rake in revenue unfairly and at the detriment of everyone else. We mark all such sites as suspicious, and they are given one final personal look before the are added to a jailing list. This list is used to temporarily blacklist visitors that were seen multiple times on several of these malicious sites. Consequently, no bids for advertisements are placed and thus no ads are shown on our part to these users, since there is no return on investment for the cost paid by the clients. The whole approach outlined in this blog post is just one of the tools in Zemanta’s arsenal for combating malicious traffic, where the focus lies in bringing quality traffic for the best possible price.
The analysis was part of my 3-month internship at Zemanta, where I worked on how to detect this type of fraud, as well as implementing our approach at scale in the existing infrastructure. The implementation was a breeze with such awesome support from the whole team. It was a great learning experience and an invaluable opportunity to work on a codebase that scales to many thousands of requests in a second. Personally, I believe that this bridging of the gap between research and industry benefits both parties immensely, and I hope to do more such collaborations in the future.
[1] Stitelman, Ori, et al. Using co-visitation networks for detecting large scale online display advertising exchange fraud. Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2013